Интерфейсы прикладного программирования (API) долгое время оставались самым консервативным компонентом 3D-графики. Стандарт Direct3D 11 был представлен еще в 2008 году, и до сих пор основная масса новых игр на ПК использует его в качестве основного и в подавляющем большинстве случаев единственного API. Этот островок стабильности в чрезвычайно быстро развивающейся индустрии, какой являются компьютерные игры, образовался отнюдь не из-за традиционализма разработчиков ПО или производителей железа. Напротив, единый стандарт Microsoft, который вытеснил из большой игры некогда могущественного соперника (OpenGL), дал возможность всем участникам рынка сконцентрировать усилия на своих прямых задачах без необходимости оптимизировать драйверы, архитектуру GPU и игровые движки под несколько API одновременно (как в былинные времена под Glide и популярный OpenGL).
Недавние потрясения в этой сфере, связанные с названиями DirectX 12 и Vulkan, вызваны, по сути, усилиями единственной компании — AMD, которая в 2013 году выпустила собственный интерфейс программирования Mantle в сотрудничестве с DICE, автором игровой серии Battlefield. В данный момент работа над Mantle прекращена, но оба универсальных API нового поколения заимствовали идеи AMD и преследуют ту же цель — более эффективно использовать вычислительные ресурсы, которые имеются в распоряжении современных GPU.
Несмотря на столь привлекательную идею Direct3D 12 (здесь и далее мы будем говорить именно о графической библиотеке в составе DirectX) и Vulkan, темп внедрения новых API оставляет желать лучшего даже по сравнению с Direct3D 11, которому потребовался чрезвычайно долгий срок, чтобы целиком переманить разработчиков с Direct3D 9. И все же создатели значительного числа громких и высокобюджетных проектов последних двух лет внедрили поддержку Direct3D 12 или Vulkan по крайней мере в виде экспериментальной или побочной функции. В конце концов, методика тестирования GPU на 3DNews уже по большей части состоит из игр с поддержкой этих API. Подходящее время для того, чтобы провести исследование и сделать промежуточные выводы о том, насколько в действительности полезны DirectX 12 и Vulkan для производительности современного железа.
Новые функции Direct3D 12 и Vulkan
О принципах, лежащих в основе Direct3D 12, и его отличиях от предыдущей версии API Microsoft, мы писали в 2014 году, когда стандарт находился на ранней стадии разработки и многие из его особенностей еще не были финализированы. Главное, что изменилось в облике Direct3D 12 с тех пор, — это набор дополнительных функций рендеринга, открытых для графических процессоров с теми или иными аппаратными возможностями.
Оставим за кадром строение конвейера рендеринга и некоторые особенности программирования под Direct3D 12, которые описаны в нашей давнишней статье. Есть лишь несколько отличительных черт нового API, которые должны волновать широкую публику. Начнем обзор с универсально значимых пунктов и закончим той самой функцией Direct3D 12 (и Vulkan), которая породила много споров, непонимания и завышенных ожиданий на страницах публикаций и форумов, — асинхронными вычислениями.
Самой привлекательной чертой Direct3D 12 и Vulkan является быстрая подготовка т. н. draw call. В то время, когда AMD стремилась популяризировать Mantle, множество людей, ранее далеких от программирования компьютерной графики, были вынуждены познакомиться с этим термином. В 3D-рендеринге так называется команда, требующая создать единственную полигональную сетку (mesh). В играх каждая модель персонажа, юнита и практически любого независимого объекта представляет собой mesh. Следовательно, чем больше таких объектов присутствует на экране, тем больше draw calls должен отдать центральный процессор. Короткая подготовка draw call в Direct3D 12 при прочих равных условиях снижает нагрузку на CPU, сокращает время бездействия графического процессора и в результате дает возможность выводить больше объектов на экран. Помогает и распределение нагрузки в многоядерной системе, которое в Direct3D 12 происходит более эффективно.
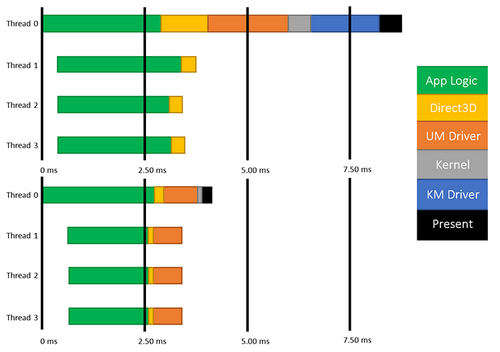
Многоядерные CPU в Direct3D 12
В целом прослойка API в стеке ПО, управляющем графическим процессором, стала тоньше по сравнению с Direct3D 11 за счет того, что многие функции, которые в Direct3D 11 выполняются в той или иной степени автоматически (такие как управление памятью, синхронизация между очередями инструкций, поддержание параллелизма нагрузки на GPU и пр.), теперь полностью принадлежат игровому движку. С одной стороны, открываются широкие возможности для оптимизации быстродействия, но с другой — программист должен иметь в виду особенности архитектуры различных GPU, чтобы избежать падения производительности.
Direct3D 12 принес массу функций рендеринга, описанных в рамках feature levels 12_0 и 12_1. Но в отличие от предыдущих итераций Direct3D, 12-я версия предназначена не для того, чтобы явить миру нечто ранее невиданное (как это было с шейдерами в Direct3D 8 и тесселяцией полигонов в Direct3D 11). Действительно, некоторые возможности feature levels 12_0 и 12_1 повышают качество определенных эффектов (к примеру, связанных с прозрачными текстурами), а иные используются в перспективных алгоритмах рендеринга (см. описание VXGI в нашем обзоре GeForce GTX 980). И все же большинство пунктов feature levels 12_0 и 12_1 служит для того, чтобы графический процессор выполнял быстрее ряд уже известных задач, которые в противном случае создают большую нагрузку на пропускную способность блоков наложения текстур, шину памяти и пр.
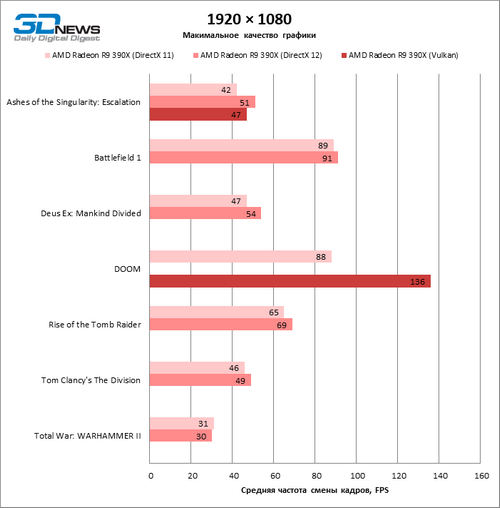
В принципе, дополнительная вычислительная мощность, которую высвобождает новая версия API, сама по себе позволяет обогатить игровую графику более детализированными текстурами и объектами. Более того, в некоторых играх под Direct3D 12 и Vulkan геймплей тесно связан с выбором API (как в Ashes of the Singularity, которая за счет множества юнитов на экране создает огромное количество draw calls). Но если поставить вопрос в формулировке «Станет ли игра выглядеть лучше, если включить в ней Direct3D 12 или Vulkan?», то на данный момент ответ будет в подавляющем большинстве случаев отрицательным. Масштаб внедрения новых API все еще слишком мал, а железо на руках пользователей слишком разнообразно, чтобы разработчики игр открыли для видеокарт, хорошо работающих под Ditect3D 12 и Vulkan, эксклюзивный доступ к заметной части визуального контента.
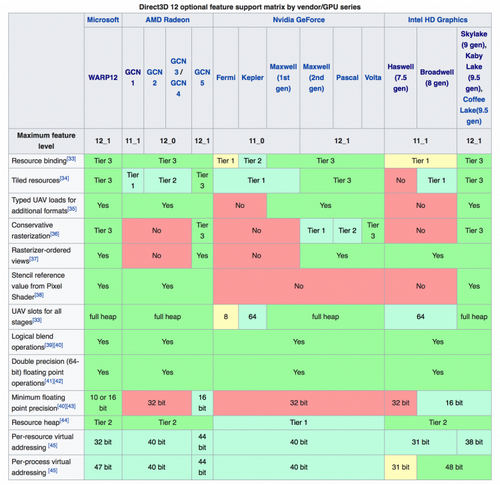
Поддержка функций рендеринга Direct3D 12 в GPU различной архитектуры (Wikipedia)
По минимальным требованиям стандарта в категорию GPU, совместимых с feature level 12_1, проходят только архитектуры Vega, Maxwell и Pascal (а также интегрированная графика Intel, начиная с процессоров Skylake), а наиболее полной поддержкой обладает Vega и Intel HD Graphics. Но и другие архитектуры AMD или NVIDIA на том или ином уровне поддерживают ряд функций из feature level 12_0 и 12_1, в том числе одни из самых полезных: Conservative Rasterization, Volume Tiled Resources и Rasterizer Ordered Views.
При этом от графического процессора не требуется совместимость с feature level 12_0 и 12_1 для работы под Direct3D 12. В действительности GPU с возможностями на уровне feature level 11_0 и 11_1, созданные в ту пору, когда Direct3D 12 не было и в помине (архитектуры Femi и Kepler от NVIDIA и GCN первого поколения от AMD), могут воспользоваться всеми преимуществами runtime-библиотеки Direct3D 12 и, потенциально, получить выигрыш в быстродействии. У AMD и NVIDIA поддержка Direct3D 12 в драйвере начинается с серий Radeon HD 7000 и GeForce GTX 400 соответственно.
Асинхронные вычисления в Direct3D 11 и Direct3D 12
Современные GPU лишь в силу привычки называются графическими процессорами. Архитектура, состоящая из большого количества исполнительных блоков (ALU, потоковых процессоров или CUDA-ядер, в терминологии различных производителей), подходит для исполнения любых программ, легко разделяющихся на независимые друг от друга цепочки операций (GP-GPU, General Purpose GPU) — будь то промышленные задачи, майнинг криптовалюты, машинное обучение и т. д.
Методы GP-GPU применяются и в играх (по меньшей мере с того времени, когда NVIDIA купила компанию — создателя «физического ускорителя» Ageia и адаптировала ее API PhysX для работы на графических процессорах), но ни одна из коммерческих игр еще не может похвастаться тем, что раскрыла потенциал неграфических расчетов в такой степени, как «демки» PhysX, которые периодически демонстрирует NVIDIA. Причина лежит на поверхности: даже лучшие GPU не обладают избытком ресурсов для того, чтобы действительно масштабные вычисления игровой физики не уничтожили частоту смены кадров. Тем более в то время, как перед разработчиками ПО и железа открылись более заманчивые перспективы — разрешение сверхвысокой четкости и VR.
Однако актуальные и потенциальные функции вычислений общего назначения в современных играх не ограничиваются физикой. SSAO (Screen-Space Ambient Occlusion), локальные отражения в экранном пространстве (Screen-Space Reflections), генерация карт теней, различные модели глобального освещения и пр. могут быть реализованы в качестве методов GP-GPU. Нетрудно заметить, что в данном случае отсутствует принципиальная граница между задачами двух типов. Она существует лишь на уровне архитектуры приложения и API, когда графика и вычисления представляют собой отдельные очереди инструкций. Именно одновременное исполнение множественных очередей инструкций лежит в основе того, что называют (не вполне корректно, но об этом позже) асинхронными вычислениями.
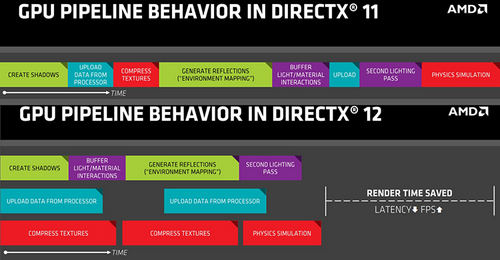
В рамках Direct3D 11 существует единственная очередь инструкций для рендеринга графики. И как бы тщательно ни была оптимизирована архитектура GPU, в процессе рендеринга неизбежно возникают «пузыри», когда шейдерные ALU простаивают, в то время как свою работу выполняют другие компоненты процессора — блоки наложения текстур, ROP, шина памяти и т. д.
В свою очередь, Direct3D 12 и Vulkan позволяют создать две отдельные очереди — для графики и вычислений соответственно (не считая очереди для передачи данных по шине PCI Express), а задача распределения ресурсов GPU между ними ложится на сам процессор и его драйвер, которые следят за возникновением «пузырей» в той или иной очереди и эффективно их закрывают за счет инструкций из соседней очереди. В общих чертах подход аналогичен функции Hyper-Threading центральных процессоров.
Прим.: на самом деле в Direct3D 12 и Vulkan можно создавать множественные очереди всех трех типов — в зависимости от того, сколько поддерживает GPU.
Осталось пояснить, почему термин «асинхронность» не лучшим образом описывает то, что происходит в процессе рендеринга с двумя очередями инструкций, которые мы осторожно назвали отдельными, но не независимыми. Корректный (и официальный для Direct3D 12) термин — Multi-Engine. Дело в том, что те процедуры, которые исполняются в «графической» и «вычислительных» очередях Direct3D 12 или Vulkan, как правило, содержат взаимные зависимости данных: исполнение инструкций в одной очереди должно быть остановлено, пока не будет получен результат определенной инструкции из другой очереди.
В таком случае можно говорить лишь об одновременном (concurrent), но не асинхронном (независимом по времени завершения) исполнении. Примером истинной асинхронности является фоновый процесс с низким приоритетом, протекающий одновременно с рендерингом кадра, — такой, как декомпрессия ресурсов, обновление карт теней в моделях глобального освещения и пр. (см. слайд AMD выше). Таким образом, термин «асинхронные вычисления» применим к узкому кругу задач, в то время как понятие Multi-Engine описывает одновременное исполнение нескольких очередей вычислительных инструкций безотносительно к структуре зависимостей между ними.
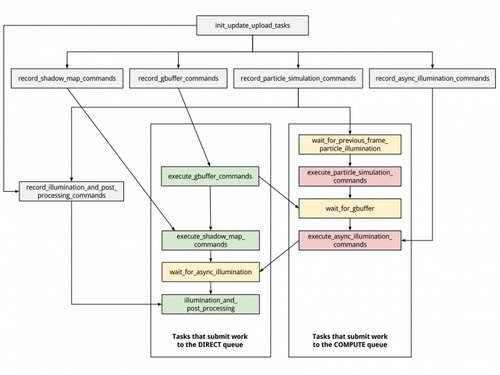
«Асинхронные вычисления» не всегда асинхронны
Multi-Engine на GPU различной архитектуры: AMD GCN
Рассмотрим животрепещущий вопрос практической реализации Multi-Engine. Популярное мнение гласит, что а) графические процессоры AMD выигрывают от применения Multi-Engine, в то время как чипы NVIDIA (включая Pascal) не могут столь же эффективно использовать его в силу архитектурных ограничений, б) среди архитектур NVIDIA только Pascal поддерживает Multi-Engine. Как нам предстоит убедиться, оба утверждения в целом верны, но полная картина далеко не столь однозначна.
Самый простой для анализа случай — это архитектура GCN (Graphics Core Next), на которой основаны все графические процессоры AMD последних лет, начиная с Tahiti (Radeon HD 7950/7970) и заканчивая Vega 10 (Radeon RX Vega 56/64). Как достоинства, так и недостатки чипов AMD в действительности располагают к применению Multi-Engine. GCN в своей основе ориентирована на вычисления GP-GPU в не меньшей степени, чем на рендеринг графики, и устроена таким образом, что добрая часть задачи насыщения GPU параллелизмом решается на уровне «железа», а не драйвера или приложения. Даже самые ранние чипы GCN обеспечивают одновременное исполнение нескольких очередей «вычислительных» команд одновременно с очередью рендеринга графики за счет командных процессоров двух типов — GCP (Graphics Command Processor) и ACE (Advanced Compute Engine). А начиная с третьего поколения архитектуры (чипы Tonga и Fiji), GCN также включает раздельные планировщики для шейдерных и «вычислительных» инструкций. В результате процессор может динамически передавать вычислительные ресурсы отдельных CU (Compute Unit — блок, содержащий 64 ALU) между несколькими очередями инструкций.
Кроме того, GCN допускает сравнительно безболезненную смену контекста CU. Смена контекста в данном случае означает, что CU, находящийся в ожидании данных от длительной операции, которой занимаются другие блоки GPU, получает от командного процессора другую работу, сохранив содержимое своих регистров в каком-либо внешнем хранилище. В GCN этим хранилищем является высокоскоростной интегрированный кеш, и процессор может пользоваться сменой контекста весьма свободно.
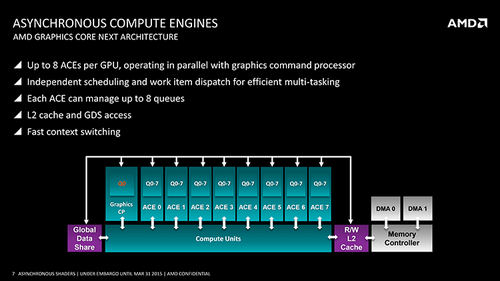
Таким образом, управляющая логика GCN способна эффективно загружать исполнительные блоки GPU за счет инструкций из отдельных очередей, заполняя даже сравнительно небольшие «пузыри» конвейера. Итоговый прирост быстродействия зависит от того, насколько часто «пузыри» возникают в режиме одной очереди. Но ведь правда, графические процессоры AMD существенно недогружены в большинстве игр по сравнению с чипами NVIDIA, и с каждым новым поколением ситуация усугубляется. Достаточно взглянуть на Radeon RX Vega 64, которая в задачах GP-GPU по меньшей мере не уступает GeForce GTX 1080 Ti, но в играх едва справляется с GeForce GTX 1080. GCN — «широкая» архитектура, требующая высокого параллелизма для полной нагрузки. Поэтому да, возможности Multi-Engine, которые открывают современные API, могут стать большим подспорьем для AMD — с большой оговоркой о том, что разработчики игр начнут их активно использовать.
Multi-Engine на GPU различной архитектуры: NVIDIA Kepler, Maxwell и Pascal
Ситуация с поддержкой Multi-Engine в графических процессорах NVIDIA далеко не столь прозрачна, как в случае с AMD. Материалы NVIDIA, находящиеся в широком доступе, не дают ясного ответа на все вопросы. С полной уверенностью можно говорить лишь о том, каким именно из GPU архитектур Kepler, Maxwell и Pascal вообще разрешено иметь дело со смешанной нагрузкой (графика/вычисления) под управлением Direct3D 12 и Vulkan. А наше представление о том, почему это так, а не иначе, основано по большей части на сторонних источниках и не претендует на истину в последней инстанции. Что поделать, такова политика этой компании, особенно когда речь идет о недостатках их продуктов.
В отличие от AMD, NVIDIA решила разделить свои GPU на преимущественно потребительские либо профессиональные модели, начиная с архитектуры Kepler. Первые изначально лишены массы вычислительных функций, бесполезных в игровых задачах (таких как быстрое исполнение расчетов двойной точности). Кроме того, на пути от архитектуры Fermi (GeForce 400/500) к Kepler, а затем Maxwell разработчики последовательно сокращали управляющую логику GPU, переложив часть функций на драйвер.
Тем не менее поддержка смешанной нагрузки даже в массовых чипах NVIDIA значительно расширилась со времен Kepler. «Мелкие» чипы архитектуры Kepler (GK10X, GeForce GTX 680 и ниже, а также GeForce GTX 770) способны работать с единственной очередью команд, будь то графика или чисто вычислительная задача (ни о каком Multi-Engine речи не идет). В «большом» Кеплере (GK110/210, GeForce GTX 780/780 Ti и GeForce GTX TITAN) и чипах Maxwell первого поколения (GK107, GeForce GTX 750/750 Ti) внедрили отдельный блок для приема «вычислительных» очередей Hyper-Q, но отдельная «вычислительная» нагрузка одновременно с графикой возможна только под проприетарным API CUDA. Кроме того, «вычислительная» очередь может задействовать один и только один из 32 слотов блока CWD (CUDA Work Distributor), распределяющего цепочки операций между отдельными SM.
Динамическое распределение мощностей между графической и «вычислительной» очередями появилось только в Maxwell второго поколения (серия GeForce 900), но существует критически важное ограничение: перераспределение происходит лишь на границе draw call, а значит, драйверу нужно выделить необходимую для той или иной задачи группу SM (Streaming Multiprocessor, блок, в который организованы CUDA-ядра) заранее. Отсюда возникают ошибки планирования, которые невозможно устранить на лету, и даже при идеальном предсказании эвристики драйвера Maxwell будет пропускать мелкие «пузыри» конвейера. Кроме того, Maxwell несет тяжелые потери от смены контекста, т. к. промежуточные результаты вычислений сохраняются в (обладающей сравнительно высокой латентностью) оперативной памяти, при этом происходит полная очистка кеша L1 и разделяемой памяти GPU. В таких условиях быстродействию не настолько сильно вредит достаточно короткий простой отдельных SM, как смена контекста.
Похоже, именно эти архитектурные ограничения побудили NVIDIA заблокировать Multi-Engine в драйвере для Kepler и Maxwell. Приложение может создать сколько угодно «вычислительных» очередей, но драйвер все равно объединит их с графической очередью. По-прежнему единственная лазейка для разработчиков — это использовать CUDA, хотя на ситуацию с распределением ресурсов и смену контекста API никак не влияет.
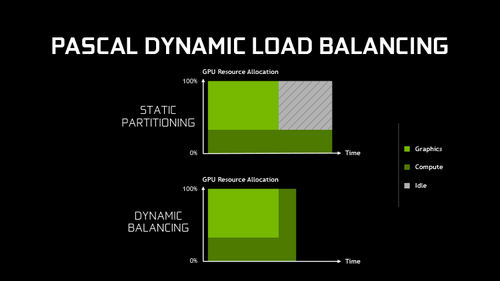
Среди «зеленых» GPU только семейство Pascal допущено к функции Multi-Engine в Direct3D 12 и Vulkan, ибо Pascal, в отличие от Maxwell, умеет передавать ресурсы SM между очередями графики и «вычислений» динамически, не дожидаясь завершения draw call. При этом цена смены контекста осталась высокой (вплоть до 0,1 мс или 170 тыс. циклов GPU в случае GeForce GTX 1070/1080!), а значит, Pascal по-прежнему ограничен в гибкости при работе с несколькими очередями команд по сравнению с GCN.
В итоге NVIDIA довольно сильно усложнила жизнь разработчикам приложений, желающим использовать Multi-Engine. GCN неприхотлива и предсказуема в плане смешанной нагрузки, но ускорители Radeon на рынке в меньшинстве. С другой стороны, видеокарты с графическими процессорами NVIDIA стоят во множестве игровых ПК и вдобавок принадлежат к нескольким поколениям с различным уровнем поддержки Multi-Engine и методами его использования. Но, к счастью для NVIDIA, ее продукты и без того не испытывают недостатка в быстродействии. Чипы Maxwell и Pascal в сравнении с процессорами GCN соответствующего класса имеют более «узкую» архитектуру с меньшим числом шейдерных ALU, а значит — не требуют столь же высокого параллелизма для полной загрузки.